Wie Active Learning die Computer-Vision-Technologie vorantreibt

Welche Bedeutung hat die Datenqualität in Computer-Vision-Projekten und welche Rolle spielen hier Ansätze wie Data-Centric-AI und Active Learning?
Computer Vision ist ein Bereich der Künstlichen Intelligenz (KI), der sich darauf konzentriert, Computern das „Sehen“ zu ermöglichen – ähnlich wie menschliches Sehen, durch die Interpretation und Verarbeitung visueller Daten. Es umfasst die Entwicklung von Algorithmen, die Bilder oder Videos analysieren können, um verschiedene Aufgaben zu erfüllen, wie Objekterkennung, Bildklassifizierung, Gesichtserkennung und mehr.
Der Erfolg von Computer-Vision-Anwendungen hängt stark von der Qualität und Vielfalt der verwendeten Trainingsdaten ab. Data-Centric-AI-Ansätze verbessern die Qualität dieser Daten, indem sie sich auf die Reinigung, Annotation und Auswahl der wirkungsvollsten Trainingsbeispiele fokussieren. Active Learning wiederum ermöglicht es, diesen Prozess zu optimieren, indem es die Auswahl und Annotation von Daten effizienter gestaltet, was besonders wichtig ist, um mit begrenzten Ressourcen die bestmöglichen Ergebnisse zu erzielen. Zusammen fördern diese Konzepte die Entwicklung leistungsfähigerer Computer-Vision-Systeme, indem sie sicherstellen, dass die Modelle mit den bestmöglichen Daten trainiert werden.
Wenn Sie mehr über Data-Centric AI erfahren möchten, empfehlen wir Ihnen den Beitrag Data-Centric AI: Mit Datenpräzision die KI-Effizienz steigern im CONET-Blog.
Im Folgenden beleuchten wir die Bedeutung von Active Learning in KI-Anwendungen:
Die Auswahl von Daten in Computer-Vision-Projekten
Grundsätzlich ist die Entwicklung performanter Machine-Learning- und Computer-Vision-Modellen hochgradig iterativ. Dies bedeutet, dass sowohl Modellarchitektur als auch Trainingsalgorithmus und Einsatzumgebung schrittweise von einem initialen „Proof of Concept“ (POC) zu einem produktiven System weiterentwickelt werden. Diese Entwicklung ist aus vielerlei Gründen notwendig, jedoch nicht hinreichend für ein komplexes KI-System, dessen wichtigste Basis eine ausreichend große Menge an qualitativ hochwertigen Daten ist.
In Computer-Vision-Projekten ist die Akquise großer Mengen an Bilddaten häufig nicht sonderlich aufwändig. Die Qualität der Daten ergibt sich dabei nicht aus der Menge, sondern aus der Vielfalt der Bilder sowie der Korrektheit der zugehörigen Annotationen. Bilder korrekt zu annotieren, bedeutet jedoch – abhängig vom konkreten Use Case – erheblichen Aufwand. So müssen beispielsweise Objekte in Bildern manuell markiert und kategorisiert werden. Dieser Annotationsprozess ist zeitaufwändig und teuer. Dies gilt insbesondere, wenn die Annotation Expertenwissen erfordert.
Die Auswahl der Daten für die Annotation wird häufig schlicht zufällig getroffen. Dies führt meist zu Redundanz und Unterrepräsentation seltener Merkmale sowie Situationen. Im Ergebnis bedeutet das einen erhöhten Aufwand in der Annotation sowie gleichzeitig reduzierte Modellperformance und Fairness. Methoden aus dem Bereich des Active Learning bieten automatisierte Lösungen zur effizienteren Auswahl dieser Daten. Sie zielen auf eine Maximierung des Informationsgewinns durch jeden neuen Datenpunkt ab und priorisieren damit automatisch unterrepräsentierte und für das Modell schwer vorherzusagende Datenpunkte. Durch diese zielgerichtete Selektion neuer Datenpunkte lassen sich Kosten reduzieren sowie performantere und fairere Modelle entwickeln.
Was ist Active Learning?
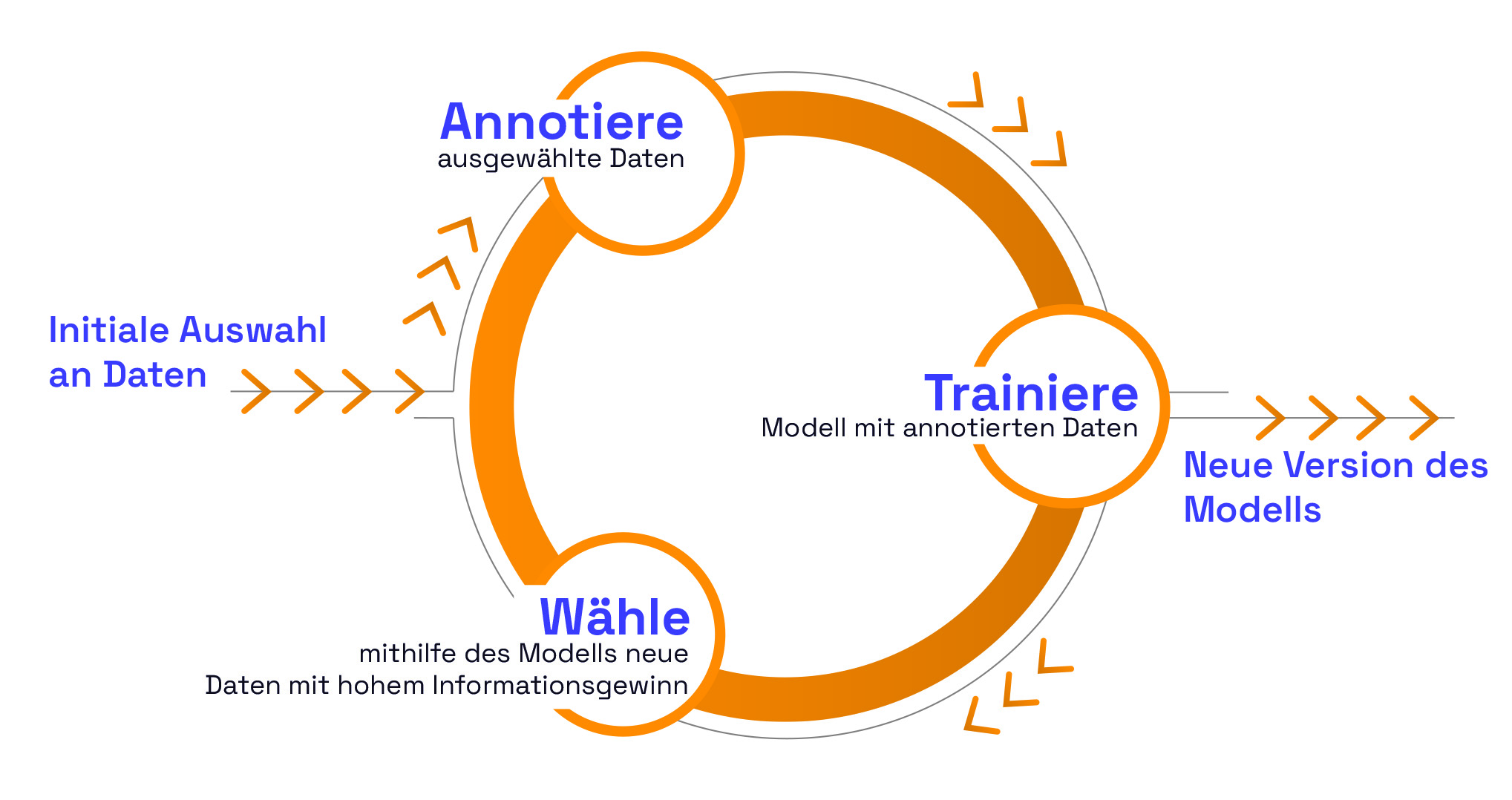
Abb. 1: Active-Learning-Zyklus. Die Datenbasis wird iterativ verbessert, indem das jeweils neueste Modell zur Auswahl neuer Daten für die Annotation verwendet wird.
Active Learning beschreibt Ansätze zur Identifikation von Daten mit maximalem Gehalt an neuen Informationen beziehungsweise minimaler Redundanz und Ähnlichkeit zu den bereits annotierten Daten. Diese Selektion geschieht durch Analyse der Modellantworten für entsprechende neue und noch nicht annotierte Daten. Ob ein neuer Datenpunkt einen hohen Informationsgehalt hat, wird dabei über ein Maß der Modellkonfidenz entschieden. Dieses drückt die relative Sicherheit einer Modellprognose aus. Die Modellkonfidenz ist typischerweise auch verantwortlich für abgeleitete Aussagen wie „Die KI ist sich zu 95% sicher“.
Wichtig zu verstehen ist dabei, dass es sich nicht um eine Wahrscheinlichkeit handelt. Ähnlich wie wir Menschen kann ein Modell durchaus sehr überzeugt von einem falschen Ergebnis sein. Gute Prognosen korrelieren jedoch in hohem Maße mit der Realität. Dies gilt unabhängig davon, ob sie von einer KI oder einem Menschen stammen.
Für die Akquise eines neuen Datenpunkts ist also die entscheidende Frage, wie sicher sich das Modell in seiner Vorhersage ist. Ist sich das Modell sehr sicher, so kann davon ausgegangen werden, dass die vorhandene Datenbasis die vorliegende Situation bereits ausreichend abdeckt oder es sich schlichtweg um einen für das Modell leicht vorherzusagenden Datenpunkt handelt. Ist die Konfidenz des Modells jedoch niedrig, so bedeutet das, dass das Modell sich unsicher ist. Es handelt sich dann mit hoher Wahrscheinlichkeit um einen seltenen beziehungsweise um einen für das Modell schwierigen Datenpunkt. Es ergibt in diesem Fall Sinn, den Datenpunkt manuell zu annotieren und dem Trainingsdatensatz hinzuzufügen.
Die Entscheidung, einen Datenpunkt zu annotieren, wird beim Active Learning letztendlich von einem Machine-Learning-Modell getroffen. Die Annotation wird dann üblicherweise von menschlichen Annotatoren übernommen. Man spricht daher von einem „human-in-the-loop“-Ansatz. Schlussendlich bedeutet es, dass wir dem ML-Modell die Möglichkeit geben, im Zweifel einen menschlichen Experten zu befragen. Auf diese Weise wird mit minimaler menschlicher Interaktion iterativ die Datenbasis und damit auch die Qualität zukünftiger Modellversionen verbessert.
Wie kann Active Learning in einem Computer-Vision-Projekt umgesetzt werden?
In vielen Projekten ist das reine Aufzeichnen von Bilddaten mit eher geringem Aufwand verbunden. So kann beispielsweise an Produktionsmaschinen durch das Anbringen von Kameras kontinuierlich Bildmaterial bereitgestellt werden. Bei vielen Anwendungen produzieren auch die Endnutzer große Mengen an nutzbarem Bildmaterial. Internet-of-Things(IoT)-Anwendungen erzeugen beispielsweise kontinuierlich Daten von vielen Endgeräten. Nicht immer handelt es sich dabei nur um Bilddaten. Das Prinzip des Active Learnings lässt sich jedoch auch auf jegliche andere Art von Daten anwenden.
Insbesondere bei IoT-Anwendungen können häufig nicht alle Bilddaten nach Hause gesendet werden. Gründe dafür sind unter anderem Einschränkungen in der Konnektivität wie Datenvolumen oder eine schlechte Verbindung, begrenzte Speicherkapazitäten auf den Edge Devices oder Kosten für die zentrale Datenhaltung. In diesen Fällen kann Active Learning direkt auf dem Edge Device verwendet werden, um Bilder mit hohem Informationsgehalt zu identifizieren sowie um Bilder mit redundanten Inhalten zu verwerfen.
Fazit
In vielen Computer-Vision-Projekten liegt eine große Menge an Bilddaten vor oder kann mit relativ geringem Aufwand akquiriert werden. Das Annotieren dieser großen Menge an Bilddaten ist allerdings zeit- und kostenintensiv. Da viele Bilder redundante Informationen beinhalten ist es zudem auch unnötig. Es stellt sich daher die Frage nach einer effizienten Selektion der Bilddaten und der damit einhergehenden Maximierung des Informationsgewinns pro annotiertem Bild. Methoden aus dem Bereich des Active Learnings bieten Lösungen dafür. Active Learning erlaubt eine effiziente und kontinuierliche Verbesserung der bestehenden Datenbasis durch automatisierte Selektion von neuen Bilddaten mit maximalem Informationsgehalt. Im Ergebnis führt dies zu performanteren und faireren Modellen bei gleichzeitig geringeren Kosten.
Möchten Sie mehr über die Einsatzmöglichkeiten von Computer Vision erfahren? Dann empfehlen wir Ihnen unsere Website zum Thema. Oder Sie kontaktieren unser PRO-Team und lassen sich kostenlos beraten. Unser Data-Intelligence-Profis stehen Ihnen gerne mit Rat und Tat zur Verfügung.